6 Databricks Integrations That Deliver Maximum Business Impact
Most companies spend big on Databricks but don’t see the returns they expect. The real difference between success and failure isn’t the analytics platform itself, but how well Databricks connects with everything else in your technology setup.
The Hidden Cost of Isolated Data Platforms
Databricks can do a lot, but when it stands alone it quickly becomes expensive. Plenty of companies learn this the hard way. Real results come from connecting Databricks to your other business systems. Comcast is a good example. They made databricks integration AWS a priority. They cut compute costs by ten times and reduced their onboarding team from five to half an engineer for 200 users, all because they understood value comes from Databricks working with their existing cloud infrastructure.
When teams treat Databricks as a standalone analytics platform, they run into trouble. Data gets moved manually, work gets duplicated, and important chances for operational excellence get missed.
AWS Integration for Databricks Success
Getting databricks integration AWS right isn’t just about running Databricks on the Amazon cloud provider. The real work is in making Databricks and AWS fit together for security, scale, and cost.
Security and Governance
Databricks uses native integration with AWS identity and access management. When you set things up right, your existing AWS security rules work with your Databricks clusters. There’s no need to invent new security silos. Data stays in your Virtual Private Cloud, and you keep total control over who gets access.
This approach makes audits easier for security teams. Familiar AWS IAM roles can be extended to Databricks clusters, so you’re not reinventing the wheel. Lots of companies find that a full security setup with Databricks actually lowers audit complexity.
Cost Control Using Native Integration
Databricks and AWS let you separate compute and cloud storage. This means you store data in S3, which is cheap and nearly unlimited, while compute resources can scale up or down as needed. You only pay for what you use, and automated policies spin down idle clusters or right-size compute as workload patterns change. Many companies see substantial cost savings just from this.
Monitoring and Observability
With AWS CloudWatch, you get one place to monitor both infrastructure and your analytics pipelines. Operations teams can check cluster node health, follow execution time for jobs, and dig into Spark telemetry. Looking at Mapping Spark metrics or the Spark driver event log gives visibility into every Databricks Job and job task on the platform.
Version Control Through Git Integration
Databricks git integration changes how teams work with analytics pipelines and notebooks. Instead of treating code as throwaway, version control brings discipline and traceability.
Why Version Control Matters
Every change in a production notebook is tracked and auditable. This matters for compliance and for keeping production reliable. Teams see better code quality and have more confidence in deployments when version control practices are in place.
It’s easier to debug and investigate results, too. If you ever need to answer which notebook version gave a certain output, Databricks Git tells you. Tracking changes helps during audits and when figuring out unexpected results.
Collaboration in Teams
With Databricks Git integration, team members can work together without stepping on each other’s toes. Branching means people can work in parallel, and merge controls (with peer review) keep the code clean. Business stakeholders feel more confident with data products when they see every change is tracked. This is a clear step up from working in silos.
Version control also means you can always go back and see what happened, who changed what, and why. It’s all there for root cause analysis and better team learning.
GitHub Integration for Professional Development Workflows
Databricks github integration brings order and teamwork to analytics development. It’s not just for software engineers—data teams gain a lot from project management and automation features.
Code Review and Quality
Before any code goes live, pull request workflows ensure another set of eyes reviews the changes. This isn’t just about catching mistakes—it’s about sharing knowledge and building a consistent standard. Many organizations see fewer production issues and better overall quality through code review.
Younger team members learn from these reviews too, which keeps the whole team growing.
Automated Deployment Pipelines
CI/CD with GitHub Actions automates testing and deployment for data pipelines. Teams that use automation see deployment times drop from days to hours, and deployments themselves become more reliable. Testing stops bugs from sneaking in, and automated deploys reduce manual mistakes, especially when releases are rushed. Rapid deployment cycles help teams stay ahead.
The Databricks CLI is a central part of this flow. It lets you manage Databricks Jobs and Pipelines automatically in GitHub Actions, tweak configuration parameters, and set custom environment variables for each environment.
One Source of Truth
You don’t have to guess which code version is running in production—GitHub repos are the single source for all production code. This clarity keeps the system reliable and makes it much easier to respond quickly when issues come up.
ServiceNow Integration for Automated Operations
Databricks servicenow integration bridges the gap between discovering a problem and fixing it. You move from manual alerts to instant, automated incident handling.
Automated Incident Management
When Databricks spots a data quality problem or a performance issue, ServiceNow integration creates an incident ticket, sets priority, and assigns it to the right team—all automatically. This cuts response time from hours to minutes.
One global bank that built out servicenow databricks integration saw compliance incidents drop by 40%. They did this by using automated workflows to detect risks and start fixes right away. The key is that integrations are built to understand business context, not just push technical alerts.
Proactive Maintenance
Databricks can run machine learning models that predict failures. ServiceNow integration then creates maintenance work orders before there’s even a problem. Companies with predictive maintenance see fewer unplanned outages and get more from their systems.
Compliance and Governance
Automating data governance and compliance makes a real difference, especially in regulated industries. With databricks integration to compliance management systems, policy violations get flagged and contained instantly, and the right people are notified.
Teams that build governance automation save time and lower compliance costs. Real-time alerts, automated incident creation and assignment, and predictive maintenance work order generation all add up to smoother operations.
Slack Integration for Real-Time Collaboration
Databricks slack integration brings updates and alerts into the channels where teams actually work. You don’t have to keep checking Databricks for job status—Slack notifications bring the information to you.
Operational Visibility
Job updates, failures, and other key events show up in the right channels, so decision-makers don’t miss anything. Teams that use Slack notifications see faster responses and better coordination. It’s important to set up notifications smartly, so you get the right amount—not so many that people tune them out.
Keeping Everyone Informed
Business and sales teams don’t have to ask if analytics are ready. They get automatic updates when key reports finish or when customer analytics are complete. This transparency builds trust in the analytics platform and keeps everyone up to date.
Solving Problems Together
When production issues come up, real-time Slack notifications include needed context—links to Databricks runs, error details, and more. Teams can jump into problem-solving together and cut down on wasted time.
AWS Amplify Integration for Custom Applications
AWS amplify integration with databricks lets you put analytics and insights right where users need them—in apps, not just dashboards or reports.
Build and Scale Applications Fast
AWS Amplify gives you serverless compute and frameworks so you can build applications quickly. When you connect Amplify to Databricks analytics engines, teams can get dashboards or even customer-facing apps up and running fast.
This is especially helpful for organizations that want to use their data for new products or services. Being able to prototype and ship features quickly lets you keep up with market needs.
Embedded Analytics
Instead of moving users to another analytics platform, you can embed Databricks-powered insights straight into existing tools. Customer service apps, for example, can show Real Time customer data pulled from Databricks.
The Databricks Data Intelligence Platform supports this with APIs that apps can use to query data, trigger jobs, or pull results as needed.
Scaling for Growth
AWS Amplify handles scaling automatically. If more users show up, you don’t have to manage extra infrastructure. This matters if you want to serve analytics to a large group or build new features on top of your data.
Organizations using these integrations often find new ways to generate revenue by offering analytics as a product or service.
Implementation Best Practices
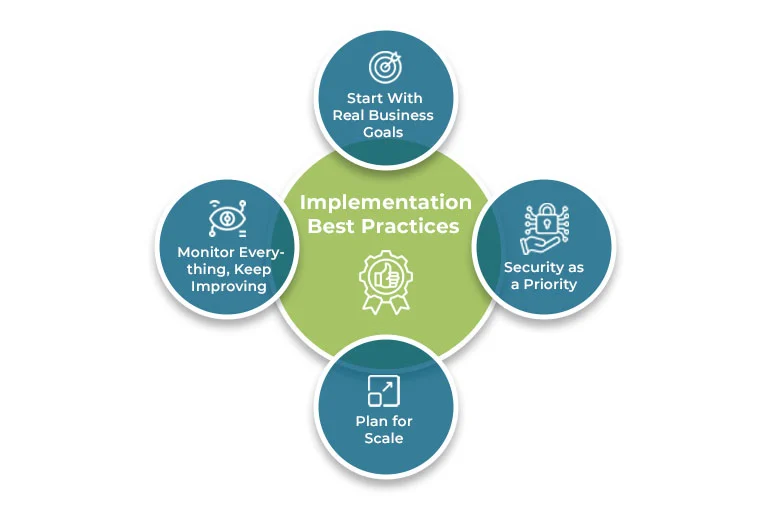 The best databricks integration projects have a few things in common.
The best databricks integration projects have a few things in common.
Start With Real Business Goals
Don’t start with the tech—start with what the business needs. The best results come from tying every integration project to specific business results, not just technical features.
Integrations built without business context usually end up being complicated but not very useful.
Security as a Priority
Every integration should follow solid security practices. That includes access controls, encryption, audit logs, and compliance checks. Regulated industries benefit from showing strong security, which builds trust internally and with regulators.
Security checklist:
- Multi-factor authentication
- Encryption in transit and at rest
- Role-based access
- Full audit logging
- Regular security reviews
Plan for Scale
Think about how data, users, and analytics complexity will grow over time. Don’t just build for what you need now.
Teams that use scalable architectures avoid expensive rebuilds later. Azure Databricks and Azure Data Factory offer similar scaling and integration options for Microsoft customers.
Monitor Everything, Keep Improving
It’s not enough to set up integrations and walk away. Keep monitoring, measuring, and improving—both technical performance and business results. Teams that use expert consultants avoid common mistakes and move faster.
Success factors:
- Business alignment
- Security framework
- Scalable architecture
Key Technologies and Integration Patterns
Databricks integration supports a wide range of use cases, from simple to complex.
Analytics Platform Capabilities
The Databricks Lakehouse brings together analytics and storage in one place. You get support for business intelligence, machine learning, and more.
Databricks on Azure offers the same for Microsoft users, with Azure Data Factory for integrations.
Databricks Technology Partners can cut setup time with ready integrations.
Databricks Delta and Databricks Delta Live Tables handle Real Time data. You can combine streaming and batch analytics for more flexibility.
Databricks SQL is there for reporting and queries.
Databricks DBU is how usage is billed.
Databricks Jobs and Pipelines, Databricks Pipeline, and Databricks Delta Live Tables Pipeline are for scheduling and automation.
Serverless compute lets you scale up or down as needed.
Databricks API and Databricks CLI enable automation and custom integration.
Databricks Data + AI and Databricks Data Intelligence Platform bring together advanced analytics, AI, and automation.
Machine Learning and MLOps
MLflow integration tracks everything from experiments to deployment. You keep an eye on accurate predictions and model drift, and retrain as needed. Built-in MLOps features help you get more from your machine learning investments.
Real Time Processing
Databricks Delta Live Tables are key for Real Time data.
You can set startOffset configuration parameter and intervalOffset configuration parameter to control how fast and often data is processed.
pipeline flow metrics and flow durations help you tune performance.
Custom Integration
Databricks API lets you build exactly what you need.
Manage job task dependencies, track task run item status, and handle integration configuration details like custom environment variables.
If you need to, use Manual connection, but default to automation.
Technical monitoring terms like Mapping Spark, attribute for Spark job, values by application, tasks by application name, telemetry types, event type, telemetry from Spark running, and metrics By default help track and manage performance.
Advanced Integration Scenarios
Some companies need more advanced setups.
Multi-Cloud
If you run on more than one cloud provider, Databricks Technology Partners can help create a unified lakehouse analytics solution.
Mapping Spark metrics and list query history API give you a full view across clouds.
Enterprise Pipelines
Large organizations use Databricks Pipeline orchestration, list pipeline events endpoint, and execution time tracking to manage complex data flows.
You’ll want to manage every event type and task run item for reliability.
Integration With Partner Solutions
Partner solutions and Databricks Technology Partners provide ready-made connectors and workflows for industry-specific needs.
Use values by application and tasks by application name to find the best fit.
How to Measure Integration Success
Measuring if Databricks Integration works means looking at:
- How often you deploy
- Failure rates
- Mean time to recovery
- Resource use
- User adoption
- Query end time
- Time to insight
Customer satisfaction often goes up when analytics platforms are connected and easy to use.
Advanced Configuration and Monitoring
Set up telemetry types and monitor pipeline flow metrics to spot issues early.
Use Spark driver event log, attribute for Spark job, and other logs for detailed troubleshooting.
Keep custom environment variables and connection instructions up to date, and automate as much as you can.
Manual connection should be a last resort.
Metrics By default and smart monitoring help you catch trends and act before problems grow.
Conclusion
Databricks alone doesn’t get you the results you want.
Value comes from connecting Databricks with AWS, Git, GitHub, ServiceNow, Slack, AWS Amplify, and more.
When you build strong Databricks Integration across your stack, you see fewer problems, better results, and smoother work.
Talk to an expert if you want to get more from Databricks.