Everything To Know About Data Mesh Architecture
“By 2026, 50% of enterprises implementing distributed data architectures will have adopted data observability tools to improve visibility over the state of the data and AI landscape.”
—Gartner, 2024
Basically, data mesh architecture is changing data management
What Is Data Mesh Architecture
Data Mesh Architecture is a way for large organizations to manage data without relying on a single, central system. Instead of sending every dataset to one warehouse or data lake, data mesh lets each team manage their own data as a product. This makes it easier for everyone in the organization to access, use, and trust the data they need.
If you’ve ever felt frustrated by slow access, siloed teams, or bottlenecks in your company’s data, you are not alone. Data mesh architecture was created to solve these exact problems.
How Data Mesh Architecture Works
In Data Mesh Architecture, every team is responsible for producing, maintaining, and sharing their own datasets. This decentralized approach means that data is no longer locked inside a single warehouse or only accessible by the central IT team.
Data Mesh Architecture uses four main principles:
- Data as a Product: Each dataset is managed like a product with its own owner, quality standards, and clear documentation.
- Domain-Oriented Ownership: The team closest to the data manages it. Sales handles sales data, finance manages finance data, and so on.
- Self-Service Data Infrastructure: Teams have the tools they need to store, process, and share data without always going through IT.
- Federated Data Governance: While teams own their data, company-wide rules ensure security, compliance, and quality.
What Is a Data Mesh Architecture Example
Imagine a global retailer using data mesh architecture. The sales department owns and manages all sales data, product teams handle product data, and logistics teams look after shipping data. Each team sets up their own data pipelines, documents their datasets, and shares data following company-wide rules.
When marketing needs sales figures, they go directly to the sales data product, not through a central team. If finance wants inventory levels, they access the product team’s dataset. This is a practical data mesh architecture example.
How Data Mesh Architecture Differs from Data Lake
Centralized data lakes store everything in one place. Teams must request access, often waiting days or weeks for the data they need. In contrast, data mesh architecture AWS, Azure, or GCP implementations let each team publish and update their own data products, making sharing and collaboration much faster.
With Data Mesh Architecture, teams can scale up without creating bottlenecks or overwhelming a central IT group.
Benefits of Data Mesh Architecture
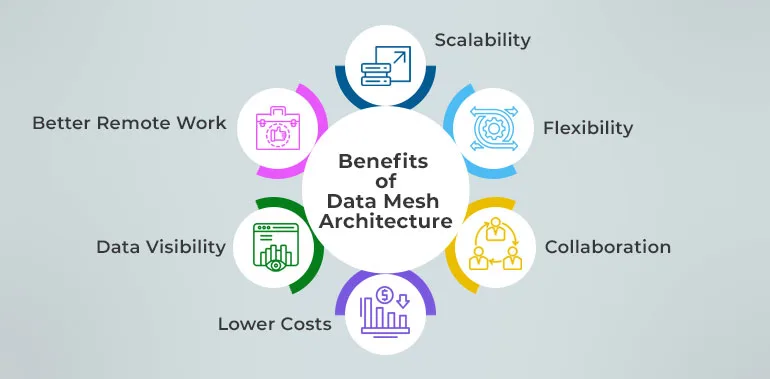 Organizations use data mesh architecture for many reasons:
Organizations use data mesh architecture for many reasons:
- Scalability: Add new domains or teams without overloading the system.
- Flexibility: Teams update their own products as business needs change.
- Collaboration: Teams work together across domains, breaking down silos.
- Lower Costs: No need to invest in massive, centralized systems.
- Data Visibility: Everyone can find and use the data they need.
- Better Remote Work: Access data from anywhere, which fits remote or hybrid teams.
AWS Data Mesh Architecture
Aws Data Mesh Architecture uses AWS tools to build decentralized data domains. Each team might use AWS Glue, S3, Redshift, or Lake Formation to create, manage, and share their data products. AWS data mesh reference architecture helps companies design secure, scalable systems that fit the AWS cloud.
Data Mesh Architecture Azure
Azure Data Mesh Architecture uses Azure Data Lake, Synapse Analytics, and other Microsoft cloud services to set up domain-based data products. Teams use Azure tools to publish, manage, and share data, while following governance policies across the business.
Data Mesh Architecture GCP
Data Mesh Architecture GCP relies on Google Cloud tools like BigQuery, Dataflow, and Pub/Sub. Teams build their own data pipelines and products, but all data is discoverable and governed by company-wide rules.
Data Mesh Architecture Snowflake
The Data Mesh Architecture snowflake involves using Snowflake’s data sharing and secure data exchange features. Each domain manages its own Snowflake instance or schema, sharing data products with other teams as needed.
Data Mesh Architecture Databricks
Data Mesh Architecture Databricks leverages Databricks’ Lakehouse platform to build decentralized, collaborative data products. Teams can use Databricks’ notebooks, Delta Lake, and ML tools to create, manage, and share data across the company.
Building a Data Mesh Architecture
- Form Data Product Teams: Assign teams to own and manage each data domain.
- Analyze Your Data: Catalog what you have and where it lives.
- Define Data Domains: Group data by business unit, geography, or other logical areas.
- Design Data Products: Create clear, documented datasets for each domain.
- Set Quality Guidelines: Make sure all teams follow the same data quality standards.
- Implement Governance: Set up policies for security, naming, and data access.
- Choose Technology: Pick tools that fit your cloud provider (AWS, Azure, GCP, Snowflake, Databricks, etc.).
- Monitor and Improve: Track how data moves, fix issues, and keep evolving the system.
Challenges in Data Mesh Architecture
Switching to Data Mesh Architecture is not just a technical change—it’s a cultural one. Teams must take responsibility for their data. Governance becomes decentralized. You need the right mix of processes, training, and technology.
Other challenges include:
- Ensuring all data products meet quality standards
- Managing security and compliance across domains
- Integrating with legacy systems
- Avoiding duplicated or conflicting data
Data Mesh Architecture and Data Observability
When data is spread across domains, you need strong data observability. Tools like Monte Carlo and DataBuck check data quality, spot anomalies, and make sure data is trustworthy. This is key for reliable reporting, analytics, and AI.
Is Data Mesh Architecture Right for You
If your organization struggles with slow reporting, siloed data, or scaling issues, data mesh architecture may help. It is especially useful for enterprises with multiple teams or business units that need to move fast and collaborate.
AWS Data Mesh Architecture, azure data mesh architecture, and data mesh architecture Databricks can all work together or separately to build a solution that fits your needs.
Choosing the Right Data Mesh Architecture
The best Data Mesh Architecture depends on your business and technology stack. Some use AWS data mesh reference architecture, others prefer data mesh architecture Snowflake or Databricks.
Think about:
- Where your data lives now
- What cloud tools you use
- How your teams are organized
- Compliance and security requirements
How Beyond Key Can Help
Moving to a Data Mesh Architecture is a big step. Our Data engineering consulting team can help you plan, build, and manage data mesh systems across AWS, Azure, GCP, Databricks, and Snowflake.
With Databricks consulting, we bring deep experience in decentralized data, Lakehouse architectures, and real-time analytics.
Next Steps for Your Data Mesh Journey
Start by assessing your data challenges. Gather your teams. Map your data domains.
Ready to explore Data Mesh Architecture AWS, Azure, or Databricks?
Talk to an expert at Beyond Key and see how our consulting can help you build a system that fits your business.
Final Thoughts
Data Mesh Architecture is not just a trend. It’s a response to the real needs of modern organizations. With the right approach, you can make your data more available, scalable, and useful—no matter how big your business gets.