
Welcome to the digital age, where data reigns supreme. But how do you tap into its power and use it effectively? Enter pipeline architecture, the efficient and reliable way to collect, process, and analyze data. In this article, we’ll explore what pipeline architecture is and why it’s so crucial for businesses to succeed.
What if you don’t focus on pipeline architecture? Without an optimized pipeline, data processing can be a nightmare. Manual spreadsheet reporting, data silos, and information overload can all hinder your organization’s growth and decision-making. With a poorly designed pipeline, you’ll likely experience lower data accuracy, incomplete data sets, and slow data delivery times. Don’t let data chaos slow you down. Embrace pipeline architecture and unlock the full potential of your data.
At its core, pipeline architecture is an architectural pattern used to process and distribute data within an organization. By breaking down data processing tasks into modular stages, organizations can scale their data processing and automate the processing of data, leading to improved accuracy, completeness, and delivery times. Data pipelines also improve data integrity and enable fast, automated data analysis.
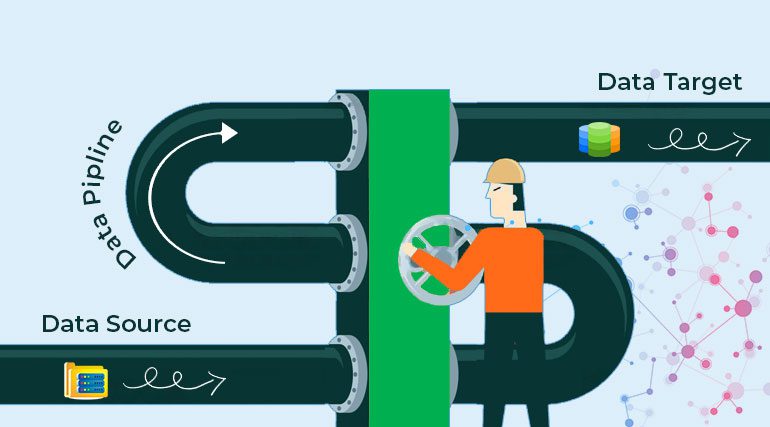
To maximize the efficiency of your data pipeline, you must consider the data flow. Your pipeline should allow for smooth and efficient data flow from data sources to data warehouses, and then to the target population. It should support a wide range of data-loading operations, including data loading from various sources, data transformations, and data loading into a data warehouse. Additionally, it should manage data lineage and data quality assurance, and support data retrieval in the form of dashboards, reports, and analytical views.
Your pipeline must also be designed to maximize the agility of your business process. It should be dynamic and able to keep up with the rapid changes in data needs and requirements. It should be physically segmented into a series of components, each with its specific responsibilities, and tightly coupled to work together as a unified whole. Finally, your pipeline should be easy to manage, deploy and monitor in a production environment.
A digital transformation without a data pipeline architecture is incomplete. It is the backbone that transforms data into valuable insights through a sequence of processing steps. This pipeline can be composed of any number of applications and platforms and can run on-premises or in the cloud.
The data pipeline has three main components: preprocessing, processing, and postprocessing.
Preprocessing is the first step in the data pipeline. It occurs before any data is sent to processing or post-processing. Preprocessing involves transforming data into a format that can be processed by the other components of the pipeline.
Processing occurs after preprocessing. It manipulates the data to produce the results that the data pipeline needs. Processing can be divided into four main categories:
Postprocessing occurs after processing. It is responsible for cleaning up the data, improving its accuracy, and rendering it ready for use. Postprocessing can be divided into four main categories:
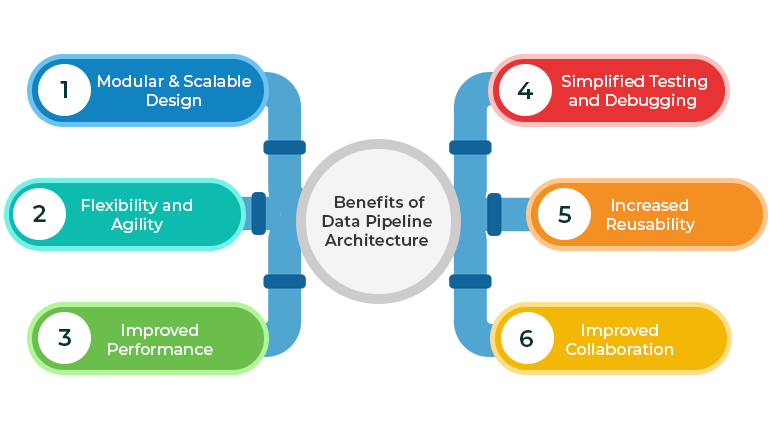
The pipeline architecture is a powerful design pattern that offers numerous benefits for software development projects. Here are some of the key advantages of using pipeline architecture:
Pipeline architecture allows developers to break down complex systems into smaller, more manageable components. Each component of the pipeline is responsible for performing a specific task, such as data processing or feature extraction. This modular approach makes it easier to scale the system as the data volume increases or the requirements change.
The modular design of pipeline architecture also makes it easier to modify and update individual components without disrupting the entire system. This allows for greater flexibility and agility in the development process, as new features can be added or existing ones modified more easily.
By breaking down a complex task into smaller components, each component can be optimized for its specific function. This can result in improved performance and efficiency, as each component can be optimized for its specific task.
Since each component of the pipeline is responsible for a specific task, testing and debugging the system becomes easier. Developers can isolate and test each component individually, making it easier to identify and fix any issues.
Pipeline architecture encourages the development of reusable components, which can be used across multiple projects. This can save time and effort in the long run, as developers can leverage existing components instead of building everything from scratch.
With a modular design, different teams can work on different components of the pipeline in parallel. This promotes better collaboration between team members, allowing for faster development and deployment.
Overall, the pipeline architecture provides a powerful framework for building scalable, flexible, and efficient software systems. Its modular design, flexibility, and performance benefits make it an ideal choice for a wide range of applications, from data processing and machine learning to web development and cloud computing.
Building a data pipeline is an essential step for organizations that want to leverage data to make informed decisions. A data pipeline is a series of processes that extract data from multiple sources, transform and clean the data, and load it into a data warehouse or database. It is a critical component of data architecture, allowing businesses to make use of the vast amounts of data they generate.
Building a data pipeline involves several best practices that ensure it is scalable, reliable, and efficient. In this answer, I will explain some of these best practices in detail.
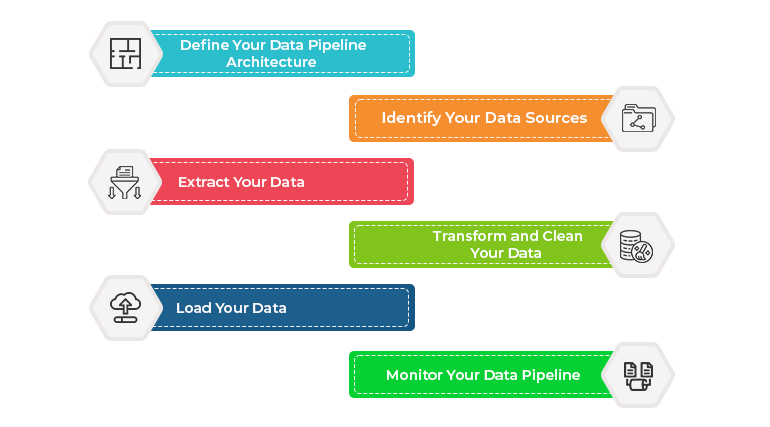
The first step in building a data pipeline is to define the architecture. There are several architectures to choose from, such as the batch processing architecture or the stream processing architecture. The architecture you choose will depend on your data requirements, the volume of data you need to process, and your budget. It is essential to consider your long-term goals when choosing your data pipeline architecture.
The next step is to identify your data sources. You need to know where your data is coming from and what type of data it is. Your data sources can be internal or external, structured or unstructured. Once you have identified your data sources, you can determine how to extract the data and what tools you need to use.
Once you have identified your data sources, the next step is to extract the data. There are several tools you can use to extract your data, such as Apache Kafka, AWS Kinesis, or Apache NiFi. It is essential to choose the right tool for your data pipeline architecture and your data requirements.
After you have extracted your data, you need to transform and clean it. This step involves converting your data into a usable format and ensuring that it is free of errors and inconsistencies. You can use tools such as Apache Spark or Apache Beam for data transformation and cleaning.
The final step in building a data pipeline is to load your data into a data warehouse or database. You need to choose the right tool for your data pipelines architecture, such as Apache Hadoop, Apache Hive, or Amazon Redshift. It is essential to monitor your data pipeline to ensure that your data is loading correctly and that there are no errors.
Monitoring your data pipeline is crucial for ensuring that it is scalable, reliable, and efficient. You need to monitor your data pipeline for errors, delays, and performance issues. You can use tools such as Apache NiFi, Prometheus, or Grafana for data pipeline monitoring.
Building a data pipeline requires careful planning and execution. You need to define your data pipeline architecture, identify your data sources, extract your data, transform and clean your data, load your data, and monitor your data pipeline. By following these best practices, you can build a data pipeline that is scalable, reliable, and efficient, enabling you to make informed decisions based on your data.
Now, when it comes to building a data pipeline, it’s essential to have a robust and scalable architecture in place. This architecture should be able to handle large volumes of data, as well as complex data transformations.
Beyond Key is here to help. As an expert in building scalable and efficient data pipelines, we can handle even the most complex data challenges. Our team has 17+ years of experience in designing and implementing data architectures that are tailored to the specific needs of their clients.
Our collaborative approach is another benefit of working. Beyond Key works closely with you to understand your unique data challenges and design a pipeline architecture that meets your specific needs. This collaborative approach ensures that the pipeline is designed with end-users in mind, making it easier to use and more efficient.
Beyond Key has a successful data pipeline track record. We have worked with a wide range of clients, from startups to large enterprises, and have delivered pipelines that have enabled clients to make data-driven decisions with confidence. Beyond Key provides these many benefits when you go with our assistance for data pipeline architecture: –
At Beyond Key, we have over 17+ years of experience maintaining self-service BI systems for a wide range of industries, including healthcare, education, insurance, eCommerce, logistics, non-profits, and more. With partnerships with top technology suppliers, we have the expertise to help you overcome any challenge and achieve your business-driven and corporate BI ambitions.
With Beyond Key on your side, you can trust that your BI solution will be tailored to your unique needs and deliver a win-win for your business.
So why wait? Contact us today to learn more about how Beyond Key can help you streamline your data analysis and reporting, and take your business to the next level.
Data pipeline architecture streamlines the movement of data between systems. It helps us identify which systems are needed and where they should be located. We can also determine how data should be transferred and prepared for analysis. Pipeline architectures enable teams to quickly access insights from large datasets.
This is important for making decisions quickly in today’s fast-paced world. By leveraging the power of data pipeline architecture, businesses can create competitive advantages. Get in touch with Beyond Key today and turn data into insights and insights into action!





