
When was the last time you heard of a business not being data-driven? Don’t remember, right? That is because all businesses nowadays are data-driven. Companies are figuring out how to mine and analyze data from diverse sources to increase their sales and profits.
But where is the safest location to store, integrate, and make the most of data from many sources?
Data lakes and data warehouses are both common methods for managing massive amounts of data. The distinction is in how organizations ingest, store, and use data. Continue reading to learn more.

A central repository for structured data collected from many sources is referred to as a Data Warehouse (DW). In Simple words, the information has already been sorted and organized and is kept on elaborate tables. Businesses may utilize DW to set up trend reports and forecasting dashboards and generate current and historical data, giving them significant insight into their business processes. Learn more about Data Warehouse Architecture.
There are various pros of Data Warehouse, and these are as follows:

Accelerated Business Intelligence:
An evaluation of relational data from Online transaction processing (OTLP) systems and business apps is provided by a data warehouse (DW) (e.g., CRM, ERP, and HRM systems).
Enhanced Data Quality and Consistency:
Data from many source systems are stored in a common format in a data warehouse due to the extract, convert, and load (ETL) process. The data’s integrity is checked after each transaction.
Historical intelligence:
End users could monitor historical changes and swiftly create reports within the needed time because DW compares new data to prior input information.
Integration with Other Sources:
This makes it suitable for small to medium-sized organizations or components of a bigger corporate structure.
Improved Decision-Making Process:
Data warehousing keeps an organized database of recent and old data, which gives decision-makers superior insights.
Let’s examine the idea of a data lake. A data lake stores data in its unprocessed form, unlike conventional databases. Typically, all the data, including raw copies of the source and processed data, is stored in a single depot. A data lake can store binary data, semi-structured data (such as CSV, JSON, logs, etc.), unstructured data (such as emails, documents, and PDFs), and structured data from relational databases (such as tables from a report) (images, audio, and video).
Data Lakes are being used more and more by businesses to store data. Let’s find out more about what Data Lake can do for us.
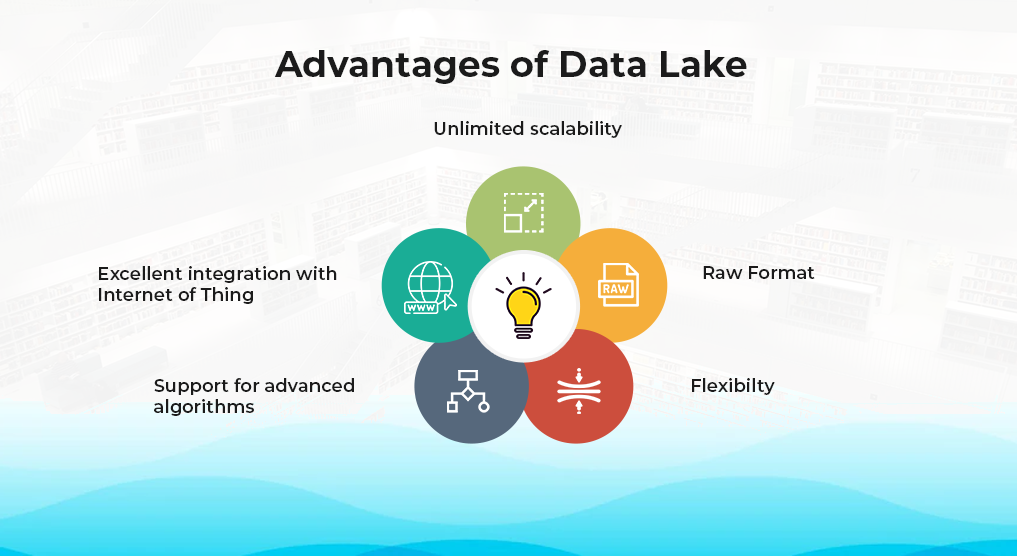
Unlimited Scalability:
Using a data lake, you may scale horizontally to meet any requirements affordably.
Raw Format:
The raw format of data from various sources is kept on file always.
Flexibility:
You can build huge heterogeneous, multiregional, and microservices systems using a DL.
Integration with ML & IoT:
Excellent Internet of Things (IoT) integration can be easily gathered and evaluated as IoT device logs and telemetry data.
Given the schema-less nature and capacity to store massive volumes of data, integration with machine learning.
Support for Advanced Algorithms:
With DL, you may use sophisticated queries and deep learning algorithms to identify exciting items or patterns.
We have done a comparative analysis between Data Lake vs Data Warehouse, there are four main differences.
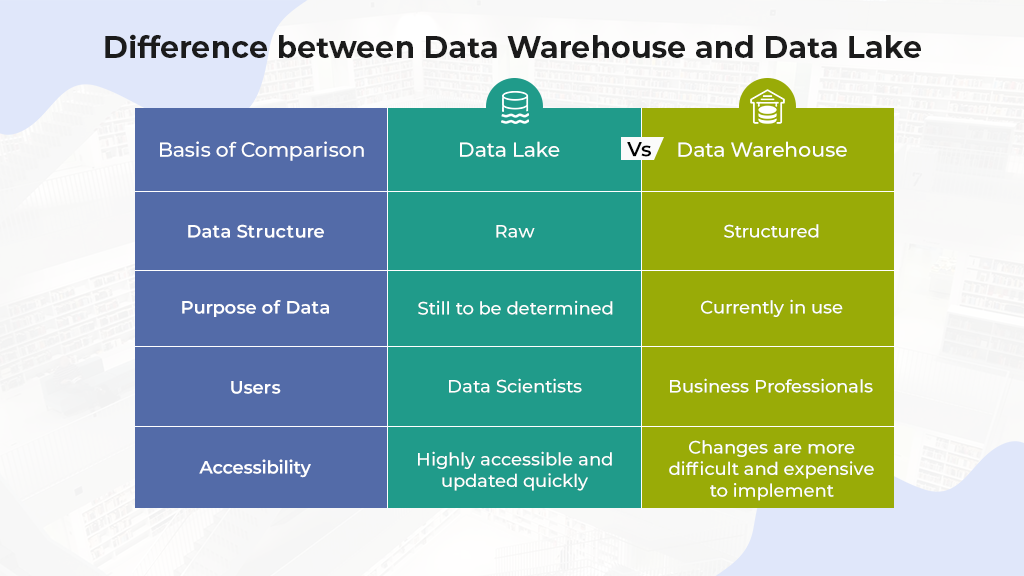
Data Structure: Raw vs Structured
Raw data is information that has yet to be processed. The raw vs. processed data structures distinction is arguably the most significant distinction between data lakes and data warehouses. Data warehouses store processed and refined data, whereas data lakes typically store raw, unprocessed data.
As a result, data lakes frequently require significantly more storage space than data warehouses. Furthermore, unprocessed, raw data is malleable and suitable for machine learning. It can be quickly assessed for any purpose. However, the risk of all that unstructured data is that data lakes may occasionally become data swamps in the scarcity of sufficient data quality and governance mechanisms.
Purpose of Data: Undetermined vs in-use
A data lake’s individual data components can have any use. Raw data enters a data lake, often with a particular purpose in mind and other times just for storage. Data lakes, as a result, are less organized and have less data filtration than their counterparts.
Data that has been altered for a particular purpose is called processed data. All data in a data warehouse has been used for a clear objective within the firm because data warehouses only store processed data. This ensures that storage capacity is not wasted on unnecessary data.
Users: Data Scientists vs Business Professionals
People not used to working with raw data frequently find it challenging to explore data lakes. It typically takes a data scientist and specialized tools to comprehend and transform raw, unstructured data for business use.
As an alternative, data preparation tools that provide self-service access to information kept in data lakes are gaining popularity.
To make processed data readable by the majority, if not all, of the personnel at a corporation, it is used in charts, spreadsheets, tables, and other formats. Processed data, such as that kept in data warehouses, simply needs the user to be knowledgeable about the subject matter.
Accessibility: Flexible vs Secure
Accessibility and usefulness apply to the usage of data repositories as a whole, not only to the data included in them. The shortage of structure in the data lake architecture makes it simple to use and modify. Furthermore, since data lakes have such few restrictions, any modifications to the data can be performed fast.
By nature, data warehouses are more organized. Because of the limits of the structure, data warehouses are difficult and expensive to manage. Still, a critical advantage of their architecture is that the data’s processing and structuring make it easier to understand.
Data warehouses are straightforward to develop and deploy right out of the box because they are integrated and governed solutions. When using a data lake, you typically employ metadata, storage, and computation from a single solution created and run by a vendor.
Data warehouses often need more structure and schema than data lakes, which often force excellent data hygiene and reduce the difficulty of accessing and consuming data.
As a result of their pre-packaged functionalities and excellent SQL support, data warehouses provide quick, useful querying, which makes them ideal for teams working on data analytics.
These are typical data warehouse technologies:
Amazon Redshift:
The first widely used (and easily accessible) cloud data warehouse, Amazon Redshift, uses source connectors to transfer data from unstructured data sources into relational storage. It is built on top of Amazon Web Services (AWS). Redshift is perfect for analytical workloads due to its columnar storage structure and processing capabilities.
Google Big Query:
Similar to Redshift, Google Big Query uses the Google Cloud, its mothership’s own cloud platform, a columnar storage structure, and parallel processing to facilitate fast querying. Big Query, in contrast to Redshift, is a serverless solution that evolves based on consumption patterns.
In contrast to Redshift or GCP, Snowflake’s cloud data warehousing capabilities are powered by AWS, Google, Azure, and other public cloud infrastructure. Snowflake, unlike Redshift, allows users to pay separate costs for computation and storage, making the data warehouse an excellent choice for teams looking for a more flexible compensation plan.
Data lakes, the do-it-yourself equivalent of a data warehouse, allow data engineering teams to choose the specific metadata, storage, and compute technologies they want to use based on the needs of their systems.
Data teams who want to create a more specialized platform with the help of a few (or more) data engineers could use data lakes.
Businesses frequently require both. Data lakes were developed due to the requirement to utilize big data and take advantage of the unprocessed, granular structured, and unstructured data for machine learning, but data warehouses are still required for business users to use for analytics.
Through these Uses Cases, let’s examine the applications of data lakes and data warehouses in various business sectors.
Healthcare
In the healthcare sector, data warehouses have long been in use. The use of data lakes offers access to both structured and unstructured data, which turns out to be more suited for healthcare firms due to the enormous amounts of unstructured data in healthcare (such as doctors’ notes, clinical data, etc.) and the requirement for real-time insights.
Education
Gathering the data about student grades, attendance, etc., can assist students in improving their track record and can also guide and predict potential issues before they occur.
Transportation
Because they can make predictions, data lakes are a fantastic source of insights. Predictions in the transportation sector can assist businesses in lowering costs and enhancing preventive maintenance.
Banking and finance
Since a data warehouse enables organized access by the entire enterprise rather than just a single data scientist, it is frequently the optimal storage architecture for these industries.
Public Sector
Developing both personal profiles and group records aids authorities in maintaining and analyzing tax records, health policies, etc.
Hospitality Industry
This industry uses data warehouses to create advertising and promotion efforts targeting customers based on their feedback and travel habits. They use DW to manage daily operations as well.
Comparison between data lake vs data warehouse is tough to settle. To meet the demands of data consumers, data teams often transition between multiple data warehouse solutions as their organization’s needs change and advance (which nowadays is nearly every functional area in the business, from Marketing and Sales to Operations and HR)
Companies require both a data warehouse and a data lake. Data lakes manage large amounts of data and gain from the raw data, unlike data warehouses, which are frequently utilized for daily and operational business decisions and operations. Data lakes are commonly employed in advanced analytics or machine learning applications. However, many businesses increasingly use both types of storage, mainly when a data lake is a foundation for a data warehouse that employs cleansed and structured data from a DL.
Did this article help you understand the differences between data lakes and data warehouses? Do you want to know more in detail? You can drop a line here and our consultants will connect with you to resolve all your queries.





